The Institute for Emerging CORE Methods in Data Science, or EnCORE, is led by the
University of California San Diego in collaboration with the University of California, Los
Angeles; University of Pennsylvania; and The University of Texas at Austin. EnCORE brings
together scientists from multiple disciplines such as statistics, mathematics, electrical
engineering, theoretical computer science, machine learning and health science, among
others.
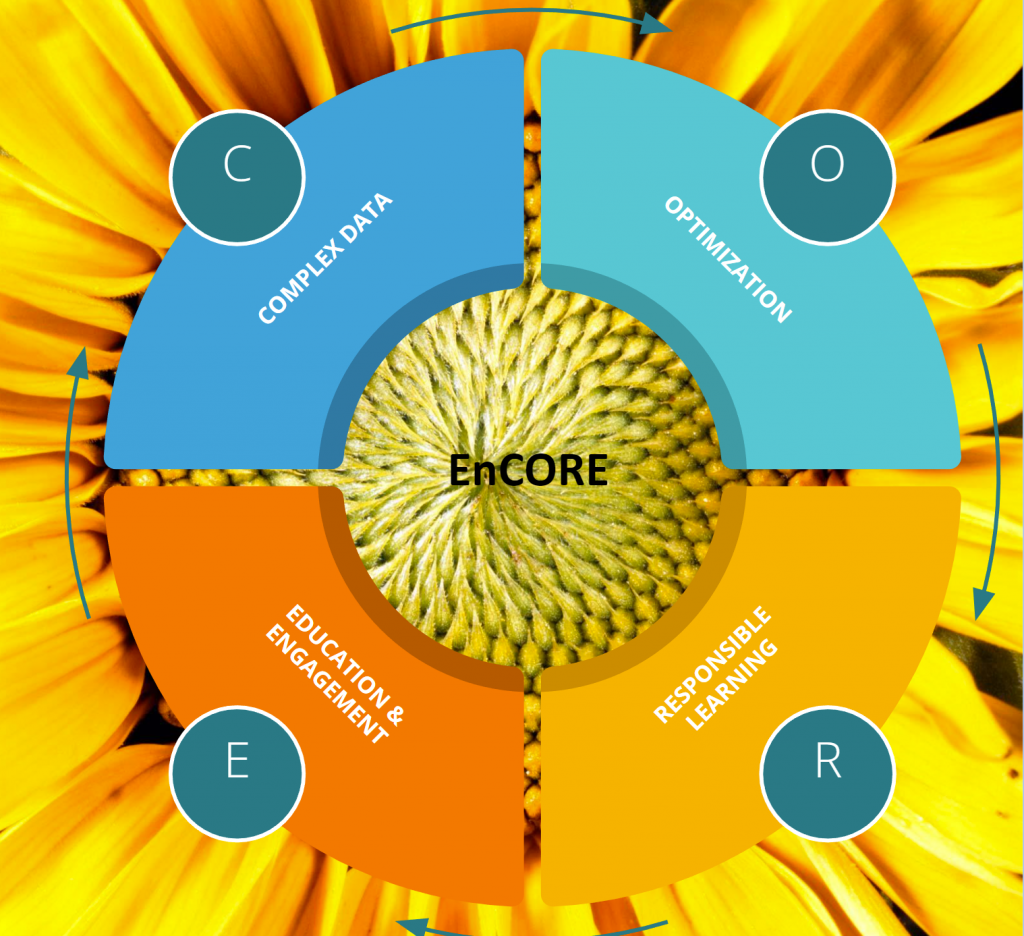
EnCORE’s team will focus on the four CORE pillars of data science: C for complexities of
data, O for optimization, R for responsible learning, and E for education and engagement.
The institute is fostering a plan for outreach and broadening participation by engaging
students of diverse backgrounds at all levels, from K-12 to postdocs and junior faculty. The
project aims to reach a wide demography of students by offering collaborative courses across
its partner universities and a flexible co-mentorship plan for multidisciplinary research.
To bring theoretical development into practice, EnCORE will work with industry partners
and domain scientists and will forge strong connections with other NSF Harnessing the Data
Revolution Institutes across the nation.
NSF’s Harnessing the Data Revolution (HDR) Big Idea is a national scale activity to enable new modes of data-driven discovery that will allow fundamental questions to be asked and answered at the frontiers of science and engineering. HDR TRIPODS aims to bring together the electrical engineering, mathematics, statistics, and theoretical computer science communities together through integrated research and training activities.





Abstract: We present a framework for aligning the local views of a possibly closed/non-orientable data manifold to produce an embedding in its intrinsic dimension through tearing. Through a spectral coloring scheme, we render the embeddings of the points across the tear with matching colors, enabling a visual recovery of the topology of the data manifold. The embedding is further equipped with a tear-aware metric that enables computation of shortest paths while accounting for the tear. To measure the quality of an embedding, we propose two Lipschitz-type notions of global distortion—a stronger and a weaker one—along with their pointwise counterparts for a finer assessment of the embedding. Subsequently, we bound them using the distortion of the local views and the alignment error between them. We show that our theoretical result on strong distortion leads to a new perspective on the need for a repulsion term in manifold learning objectives. As a result, we enhance our alignment approach by incorporating repulsion. Finally, we compare various strategies for the tear and repulsion enabled alignment, with regard to their speed of convergence and the quality of the embeddings produced.
This is joint work with my advisors Gal Mishne and Alex Cloninger at UCSD.
Abstract: In this talk, I will consider an online-learning problem, called Online Clustering with Moving Costs, at which a learner maintains a set of facilities over rounds so as to minimize the connection cost of an adversarially selected sequence of clients. The learner is informed on the positions of the clients at each round only after its facility-selection and can use this information to update its decision in the next round. However, updating the facility positions comes with an additional moving cost based on the moving distance of the facilities. I will be presenting the first (polynomial-time) approximate-regret algorithm for this setting through a combination of different algorithmic techniques such as HST embeddings, the FTRL framework with a dilated entropic regulariser as well as a novel rounding scheme.
Abstract: Despite the success of Transformers on language understanding, code generation, and logical reasoning, they still fail to (length) generalize on basic arithmetic tasks such as addition and multiplication. A major reason behind this failure is the vast difference in structure of numbers versus text; for example, numbers are associated with a specific significance order that plays a role in calculating the answer. In contrast, for text, such symmetries are quite unnatural. In this work, we propose to encode these semantics explicitly into the model via appropriate data formatting and custom positional encodings. To further elucidate the importance of explicitly encoding structure, in a simplified linear setting, we prove that standard positional encodings even when trained with augmentations to implicitly induce structure fail at such generalization, whereas enforcing structure via positional encodings succeeds.
Bio: Mahdi Sabbaghi is a second year PhD student at UPenn, department of Electrical and System Engineering, supervised by Professors Hamed Hassani and George Pappas. Previously he obtained a B. Sc. degree in Electrical Engineering as well as a B. Sc. degree in Physics from the Sharif University of Technology, in Tehran.
Abstract: We consider the problem of private estimation of U statistics. U statistics are widely used estimators that naturally arise in a broad class of problems, from nonparametric signed rank tests to subgraph counts in random networks. Despite the recent outpouring of interest in private mean estimation, private algorithms for more general U statistics have received little attention. We propose a framework where, for a broad class of U statistics, one can use existing tools in private mean estimation to obtain confidence intervals where the private error does not overwhelm the irreducible error resulting from the variance of the U statistics. However, in specific cases that arise when the U statistics degenerate or have vanishing moments, the private error may be of a larger order than the non-private error. To remedy this, we propose a new thresholding-based approach that uses Hajek projections to re-weight different subsets. As we show, this leads to more accurate inference in certain settings.
Abstract: We derive the first finite-time logarithmic Bayes regret upper bounds for Bayesian bandits, for BayesUCB and Thompson Sampling. In Gaussian and Bernoulli multi-armed bandits, we obtain $O(c_\Delta \log n)$ and $O(c_h \log^2 n)$ upper bounds for an upper confidence bound algorithm, where $c_h$ and $c_\Delta$ are constants depending on the prior distribution and the gaps of bandit instances sampled from it, respectively. The latter bound asymptotically matches the lower bound of Lai (1987). Our proofs are a major technical departure from prior works, while being simple and general. The key idea in our proofs is to conduct a frequentist per-instance analysis with Bayesian confidence intervals, and then integrate it over the prior.
Our results provide insights on the value of prior in the Bayesian setting, both in the objective and as a side information given to the learner. They significantly improve upon existing $\tilde{O}(\sqrt{n})$ bounds, which have become standard in the literature despite the logarithmic lower bound of Lai (1987).
Abstract: We study the problem of characterizing optimal learning algorithms for playing repeated games against an adversary with unknown payoffs. In this problem, the first player (called the learner) commits to a learning algorithm against a second player (called the optimizer), and the optimizer best-responds by choosing the optimal dynamic strategy for their (unknown but well-defined) payoff. Classic learning algorithms (such as no-regret algorithms) provide some counterfactual guarantees for the learner, but might perform much more poorly than other learning algorithms against particular optimizer payoffs.
In this paper, we introduce the notion of asymptotically Pareto-optimal learning algorithms. Intuitively, if a learning algorithm is Pareto-optimal, then there is no other algorithm which performs asymptotically at least as well against all optimizers and performs strictly better (by at least $\Omega(T)$) against some optimizer. We show that well-known no-regret algorithms such as Multiplicative Weights and Follow The Regularized Leader are Pareto-dominated. However, while no-regret is not enough to ensure Pareto-optimality, we show that a strictly stronger property, no-swap-regret, is a sufficient condition for Pareto-optimality.
Proving these results requires us to address various technical challenges specific to repeated play, including the fact that there is no simple characterization of how optimizers who are rational in the long-term best-respond against a learning algorithm over multiple rounds of play. To address this, we introduce the idea of the asymptotic menu of a learning algorithm: the convex closure of all correlated distributions over strategy profiles that are asymptotically implementable by an adversary. Interestingly, we show that all no-swap-regret algorithms share the same asymptotic menu, implying that all no-swap-regret algorithms are “strategically equivalent”.
This talk is based on work with Jon Schneider.
Abstract: We consider crowd-based metric learning from preference comparisons, where given two items, a user prefers the item that is closer to their latent ideal item. Here, “closeness” is measured with respect to a shared but unknown Mahalanobis distance. Can we recover this distance when we can only obtain very few responses per user?
In this very low-budget regime, we show that generally, nothing at all about the metric is revealed, even with infinitely many users. But when the items have subspace cluster structure, we present a divide-and-conquer approach for metric recovery, and provide theoretical recovery guarantees and empirical validation.
This is joint work with Zhi Wang (UCSD) and Ramya Korlakai Vinayak (UW–Madison).
Abstract: We investigate the concept of effective resistance in connection graphs, expanding its traditional application from undirected graphs. We propose a robust definition of effective resistance in connection graphs by focusing on the duality of Dirichlet-type and Poisson-type problems on connection graphs. Additionally, we delve into random walks, taking into account both node transitions and vector rotations. This approach introduces novel concepts of effective conductance and resistance matrices for connection graphs, capturing mean rotation matrices corresponding to random walk transitions. Thereby, it provides new theoretical insights for network analysis and optimization.
This is based on a joint work with Alexander Cloninger, Gal Mishne, Andreas Oslandsbotn, Sawyer Jack Robertson and Yusu Wang.
Abstract: We study the approximability and inapproximability of Strict-CSPs. An instance of the Strict-CSPs consists of a set of constraints over a set of variables and a cost function over the assignments. The goal is to find an assignment to the variables of minimum cost which satisfies all the constraints. Some prominent problems that this framework captures are (Hypergraph) Vertex Cover, Min Sum k-Coloring, Multiway Cut, Min Ones, and others.
We focus on a systematic study of Strict-CSPs of the form Strict-CSPs(H), that is, Strict-CSPs where the type of constraints is limited to predicates from a set H. Our first result is a dichotomy for approximation of Strict-CSPs(H), where H is a binary predicate, i.e., a digraph. We prove that if digraph H has bounded width, then Strict-CSPs(H) is approximable within a constant factor (depending on H); otherwise, there is no approximation for Strict-CSPs(H) unless P=NP.
Second, we study the inapproximability of Strict-CSP and present the first general hardness of approximation for Strict-CSP. More precisely, we prove a dichotomy theorem that states every instance of Strict-CSP(H) (H being a digraph) is either polynomial-time solvable or APX-complete. Moreover, we show the existence of a universal constant 0<\delta<1 such that it is NP-hard to approximate Strict-CSP(H) within a factor of (2-\delta) for all digraphs H where Strict-CSP(H) is NP-complete.
Abstract: A recent line of research has established a novel desideratum for designing approximatelyrevenue-optimal multi-item mechanisms, namely the buy-many constraint. Under this constraint, prices for different allocations made by the mechanism must be subadditive implying that the price of a bundle cannot exceed the sum of prices of individual items it contains. This natural constraint has enabled several positive results in multi-item mechanism design bypassing well-established impossibility results. Our work addresses a main open question from this literature involving the design of buymany mechanisms for multiple buyers. Our main result is that a simple sequential item pricing mechanism with buyer-specific prices can achieve an O(log m) approximation to the revenue of any buy-many mechanism when all buyers have unit-demand preferences over m items. This is the best possible as it directly matches the previous results for the single-buyer setting where no simple mechanism can obtain a better approximation. Our result applies in full generality: even though there are many alternative ways buy-many mechanisms can be defined for multibuyer settings, our result captures all of them at the same time. We achieve this by directly competing with a more permissive upper-bound on the buy-many revenue, obtained via an ex-ante relaxation.
Abstract: Since its inception in 1982, Oja’s algorithm has become an established method for streaming principle component analysis (PCA). We study the problem of streaming PCA, where the data-points are sampled from an irreducible, aperiodic, and reversible Markov chain. Our goal is to estimate the top eigenvector of the unknown covariance matrix of the stationary distribution. This setting has implications in scenarios where data can solely be sampled from a Markov Chain Monte Carlo (MCMC) type algorithm, and the objective is to perform inference on parameters of the stationary distribution. Most convergence guarantees for Oja’s algorithm in the literature assume that the data-points are sampled IID. For data streams with Markovian dependence, one typically downsamples the data to get a “nearly” independent data stream. In this paper, we obtain the first sharp rate for Oja’s algorithm on the entire data, where we remove the logarithmic dependence on the sample size, resulting from throwing data away in downsampling strategies.
Abstract: Monotonicity testing of Boolean functions over the n-width, d-dimensional hypergrid is a classic problem in property testing, where the goal is to design a randomized algorithm which can distinguish monotone functions from those which are far from any monotone function while making as few queries as possible. The special case of n = 2 corresponds to the hypercube domain. Here a long line of works exploiting a very interesting connection with isoperimetric inequalities for Boolean functions culminated in a non-adaptive tester making ~O(d^{1/2}) queries in a celebrated paper by Khot, Minzer, and Safra (SICOMP 2018). This is known to be optimal for non-adaptive testers. However, the general case of hypergrids for n > 2 remained open. Very recently, two papers (Black-Chakrabarty-Seshadhri STOC 2023 and Braverman-Khot-Kindler-Minzer ITCS 2023) independently obtained ~O(poly(n) d^{1/2}) query testers for hypergrids. These results are essentially optimal for n < polylog(d), but are far from optimal for n >> polylog(d).
This talk covers our most recent result (appearing at FOCS 2023) which obtains a non-adaptive d^{1/2+o(1)} query tester for all n, resolving the non-adaptive monotonicity testing problem for hypergrids, up to a factor of d^{o(1)}. Our proof relies on many new techniques as well as two key theorems which we proved in earlier works from SODA 2020 and STOC 2023.
Abstract: Despite efforts to align large language models (LLMs) with human values, widely-used LLMs such as GPT, Llama, Claude, and PaLM are susceptible to jailbreaking attacks, wherein an adversary fools a targeted LLM into generating objectionable content. To address this vulnerability, we propose SmoothLLM, the first algorithm designed to mitigate jailbreaking attacks on LLMs. Based on our finding that adversarially-generated prompts are brittle to character-level changes, our defense first randomly perturbs multiple copies of a given input prompt, and then aggregates the corresponding predictions to detect adversarial inputs. SmoothLLM reduces the attack success rate on numerous popular LLMs to below one percentage point, avoids unnecessary conservatism, and admits provable guarantees on attack mitigation. Moreover, our defense uses exponentially fewer queries than existing attacks and is compatible with any LLM.
Abstract: We study the design of embeddings into Euclidean space with outliers. Given a metric space $(X,d)$ and an integer $k$, the goal is to embed all but $k$ points in $X$ (called the “”outliers””) into $\ell_2$ with the smallest possible distortion $c$. Finding the optimal distortion $c$ for a given outlier set size $k$, or alternately the smallest $k$ for a given target distortion $c$ are both NP-hard problems. In fact, it is UGC-hard to approximate $k$ to within a factor smaller than $2$ even when the metric sans outliers is isometrically embeddable into $\ell_2$. We consider bi-criteria approximations. Our main result is a polynomial time algorithm that approximates the outlier set size to within an $O(\log^2 k)$ factor and the distortion to within a constant factor.
The main technical component in our result is an approach for constructing a composition of two given embeddings from subsets of $X$ into $\ell_2$ which inherits the distortions of each to within small multiplicative factors. Specifically, given a low $c_S$ distortion embedding from $S\subset X$ into $\ell_2$ and a high(er) $c_X$ distortion embedding from the entire set $X$ into $\ell_2$, we construct a single embedding that achieves the same distortion $c_S$ over pairs of points in $S$ and an expansion of at most $O(\log k)\cdot c_X$ over the remaining pairs of points, where $k=|X\setminus S|$. Our composition theorem extends to embeddings into arbitrary $\ell_p$ metrics for $p\ge 1$, and may be of independent interest. While unions of embeddings over disjoint sets have been studied previously, to our knowledge, this is the first work to consider compositions of {\em nested} embeddings.
Abstract: Graphs arising in statistical problems, signal processing, large networks, combinatorial optimization, and data analysis are often dense, which causes both computational and storage bottlenecks. One way of sparsifying a weighted graph, while sharing the same vertices as the original graph but reducing the number of edges, is through spectral sparsification. We study this problem through the perspective of RandNLA. Specifically, we utilize randomized matrix multiplication to give a clean and simple analysis of how sampling according to edge weights gives a spectral approximation to graph Laplacians, without requiring spectral information. Through the CR−MM algorithm, we attain a simple and computationally efficient sparsifier whose resulting Laplacian estimate is unbiased and of minimum variance. Furthermore, we define a new notion of additive spectral sparsifiers, which has not been considered in the literature.
Abstract


